AI Academy: Intro to AI and Machine Learning
Welcome to Posh’s AI Academy Series!
Download the AI Checklist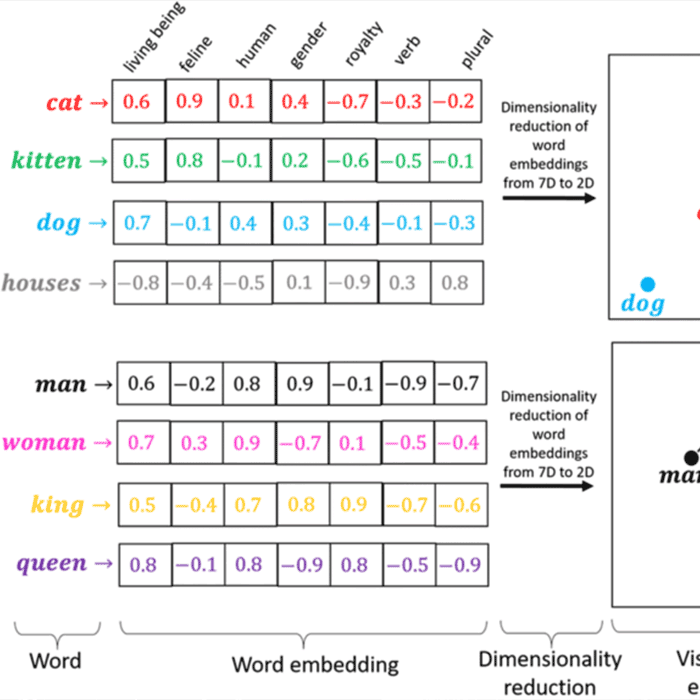
AI Academy: Intro to AI and Machine Learning
Overview
Welcome to Posh’s AI Academy Series! As summer closes and school is getting back in session, Posh’s AI Academy will help you get up to speed on AI and machine learning technologies and how they can solve business challenges. No PhD required! Over the next few blog posts, we’ll introduce key AI concepts and technologies with their enterprise applications.
First up is an intro to AI and Machine Learning. By the end of this blog post, you’ll have a better understanding of what exactly AI and machine learning are, including their key technical concepts and how they fit into an enterprise.
A Brief History of AI

So what exactly is AI? From an academic perspective, it’s a broad area of research spanning philosophy, cognitive science, applied math, computer science, and many other disciplines. The field of AI aims to both understand and build intelligent entities. While questions about intelligence and sentience can be traced back to ancient philosophers, AI as an academic discipline was formally established in 1956 at a workshop held at Dartmouth College.
Early AI research focused on developing expert systems, which consisted of a knowledge base and inference engine. These solutions struggled to scale due to the lack of computational resources and the significant amount of human effort required to collect, organize, and store knowledge in a format that could be used by inference engines.
Most modern AI solutions are applications of machine learning and deep learning models. Many of the models and technologies that power AI solutions today have actually been around since the 1950s. Recent advances in computational processing and big data have made these models tractable and viable for industry use. As a result, many exciting applications have emerged. You have AI discovering new drugs to treat COVID, writing fake blogs, trading on the stock market, driving public transportation vehicles, and even generating rap lyrics. As fundamental AI research moves forward at a rapid and seemingly exponential pace, novel and exciting applications are emerging.
An Enterprise Definition of AI
So after all this, you may still be wondering: what exactly is AI? The academic definition of AI encompasses many different research problems. To align AI specifically to enterprise use cases I’d like to propose the following definition:
AI solutions enable situational decision-making at scale in order to support optimal business outcomes.

This definition aims to separate out the purpose of an AI solution from its implementation, which may include a mixture of models, logic, and engineered features. I also prefer this definition as it highlights three key concepts that make AI valuable in the enterprise: context, scale, and purpose.
If business logic can be easily expressed and hard-coded, an AI solution would be both redundant and needlessly complex. Ironically, the original expert systems often used complex nested if-else structures in their inference engines to convert business rules into decision predictions. While effective, these solutions were tedious to build and hard to update as business rules changed or more complex scenarios emerged.
AI solutions also offer value at scale, where traditionally it is expensive to make decisions due to human and/or resource costs. As AI solutions scale with data and usage, the marginal cost for decisions drop. Finally, AI solutions are valuable when scoped to solve specific business problems. In a future post, we’ll provide a framework that will help frame business problems for AI solutions.
Key AI Concepts
Common Terms and Vocabulary
In this section, we are going to get a bit more technical and introduce some key concepts. As mentioned earlier, AI solutions are not monolithic and are often composed of models and engineered features. Let’s start with the concept of a model. A model is a mathematical function or set of functions whose primary purpose is to make predictions. Given a set of inputs (which can be text, images, tabular data, etc) the model will produce an output. Outputs are generally continuous or discrete values that can represent things like prices, temperature, sentiment labels, news topics, and many other prediction categories. This leads us to our first key AI concept: representation.
AI models only operate on numeric values. Inputs like text, images, and video need to be converted into some sort of numerical representation that the model can process. Likewise, if the expected output is discrete (e.g. positive or negative sentiment label), it will also need to be mapped to a numerical representation.
Taking a step back, a key challenge in developing an AI solution is first understanding how to represent the problem at hand to the model. A common approach is identifying analogous tasks. For example, imagine you want to build a web service that identifies dog breeds from uploaded user pictures. This problem has been explored at length in the AI academic literature and is known as image classification. In a future post, we’ll further explore common AI tasks in natural language processing and computer vision that may be useful in framing existing business problems.

Source: https://medium.com/@hari4om/word-embedding-d816f643140
Returning back to the concept of representation and inputs, the next idea I want to focus on is input features. A feature is another way describing specific types of inputs we provide to our models. Traditionally a feature is a measurable property of an observable phenomenon. For example, economists might use the Gini coefficient (a measure of wealth disparity) and the country’s GDP in their economic models. In AI models, the concept of features is a bit looser and covers a wide range of numerical representations. For example, text can be represented as a list of floating-point values, known as word embeddings (which we’ll explore deeper in a future post). Images can be represented as a flat list of RGB pixel values.
Where machine learning and deep learning differ from traditional modeling approaches, is that the machine is able to learn (through a process called training) how to best utilize the input features in order to make accurate predictions. Machine learning methods are often called black boxes because it is difficult to identify the relationship between input features and the model’s predictions. In contrast, a social scientist or medical researcher will care deeply about the inputs (usually known as independent variables) and understanding their relationship to the dependent variable being predicted. Does a country’s GDP affect its wealth inequality or can a specific gene inhibit cancer? Despite the lack of explainability, machine learning models are valuable in enterprise settings because they can learn to make highly accurate predictions for a variety of use cases. There is also ongoing research in explainability that aims to better decipher and contextualize the predictions made by machine learning models.
The “Learning” in Machine Learning/Deep Learning
This leads us to our most important concept: learning. Central to both machine learning and deep learning, learning is the process through which the model is trained to make predictions. It is also the process of how a model becomes “intelligent”.
There are three* primary learning paradigms: supervised learning, unsupervised learning, and reinforcement learning.

Source: https://www.kdnuggets.com/2017/11/3-different-types-machine-learning.html
The most successful learning approach is supervised learning. Supervised learning is used for identifying cancer in medical scans, targeting the sentiment of product reviews, filtering spam emails, and many other use-cases. Supervised learning expects labeled data. The labels or output categories must be known in advance and provided to the model. The model is then trained on labeled examples. Multiple examples of each category are provided to the model during the training process and after each prediction the model checks for accuracy against the training labels and updates itself accordingly. In our dog breed classification examples, the labels would be the specific dog breeds. The model would be provided with multiple images of, say, beagles, and German Shepherds. During this training and through these examples, the model would learn the key features that can identify beagles vs German Shepherds.

The next category of learning is known as unsupervised learning. The key distinction between supervised and unsupervised learning is that the model does not know in advance the labels or categories it needs to predict when training. Unsupervised learning looks for underlying patterns in the data provided to it and generates clusters based on similarities it finds. It is then up to the user (usually a subject matter expert) to make sense of the generated clusters and label the clusters. An example of unsupervised learning is topic analysis. Imagine you have a bunch of news articles and want to organize them. Topic analysis would attempt to cluster the articles based on common words and key phrases and generate topics like sports, financial news, and politics. Unsupervised research is often used for exploratory use-cases or the preliminary step in organizing unlabeled data. It is often not as effective as supervised learning as the model doesn’t know in advance the categories that are most useful for the user. However, unsupervised learning offers the most promise as most businesses don’t have quality labeled data.

The final category is reinforcement learning. Reinforcement learning has found great success in defeating the Go champion, furthering self-driving cars and robotic control. In a reinforcement learning system, an agent is attempting to learn how to optimally complete a task in a defined environment. Reinforcement learning differs significantly from the above two learning strategies. Reinforcement learning requires an environment, a defined action space, and the ability for the agent to capture full or partial state information of the surrounding environment at each time step. The agent learns by attempting to maximize an external reward function.

Machine Learning vs Deep Learning
Now that you have a sense of some of the key terminology and concepts behind AI models, let’s look at the difference between machine learning and deep learning. Machine learning consists of various algorithms and models which have hyperparameters that can be tuned. Hyperparameters allow the model to be customized to best fit the provided training data in order to make accurate predictions. Additionally, the machine learning scientist will spend time carefully selecting, normalizing, and identifying which input features are useful for producing generalizable predictions. This process is known as feature extraction and often can be more an art than a science. Common machine learning models include: logistic regression, support vector machines, naive Bayes, random forests, and gradient tree boosting.
Deep learning is a subfield of machine learning which focuses on the usage of artificial neural networks (also known as neural networks). Inspired by neurons in the brain, neural networks are a graph of computational nodes (neurons). Each node takes in inputs, performs a mathematical operation and produces outputs which in turn are fed into another neuron. Neurons are organized into “layers”, where each layer performs a different transformation on the information passing through it. The “deep” in deep learning refers to the multiple hidden layers in the neural network.
In contrast to machine learning, deep learning doesn’t require feature extraction or hyperparameter tuning. The various layers in the deep learning model learn to extract features and make accurate predictions. Let’s take for example our dog classifier. Traditionally image recognition required the manually computed features like the segmentation of facial features (eyes, nose, ears, etc). Various components were extracted from the image and then the model would learn which combinations of segments and specific properties of the segments (contrast, contour, shape, etc) corresponded with various dog breeds. In a deep learning model, you pass in just the image and various layers learn to extract features of the image that best help the model differentiate between the breeds. While it’s hard to identify what exactly each layer is learning, we can visualize the layer outputs. These visualizations show that layers learn to automatically pick up on various cues in the image like the shape of the nose and ears and placement of eyes.

Neural networks theoretically are universal function approximators and can learn any continuous function provided enough data. Deep learning has gained popularity in the past few years and is often the default approach for most AI modeling. This is due to the fact that deep learning models are robust, can process large amounts of data, and post state-of-the-art results across nearly all tasks. Large models trained on large datasets end up performing very well. For example, the recent OpenAI GPT-3 language model consists of 96 layers and 175 billion parameters! This model has generated much hype for its ability to write news articles, write code to build websites, and do many other exciting things.
There are limitations to deep learning, however. It can be very expensive to train, requiring massive amounts of GPU and compute resources. Open AI’s GPT-3 was trained on 570 GB of data and cost 12 million dollars to train. While most deep learning models are not that expensive, they usually require GPU resources and significant amounts of labeled data.
Conclusion
Thanks for hanging in there. Hopefully, you have a better understanding of AI and some of its key concepts. Over the course of AI Academy, we’ll dive deeper in many of these ideas. In upcoming posts, you’ll learn more about conversational AI and NLP, how to frame business challenges for AI solutions, and many other interesting things at the intersection of AI and the enterprise.



Blogs recommended for you

April 26, 2023
Employee Spotlight: Katie Krajovic; Research Scientist II
Read More
Employee Spotlight: Katie Krajovic; Research Scientist II

.png)
December 29, 2023
Harness the Power of AI for Call Centers
Read More
Harness the Power of AI for Call Centers


